GROUP BY
The GROUP BY command is used to group rows with the same value in a specified column and perform aggregate functions on those groups.
For Example:
To count how many records share the same salary in the employees table,
select salary, count(salary) from employees group by salary;
Result:
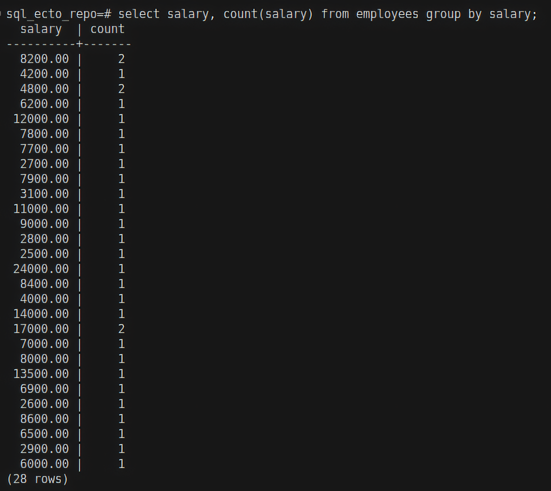
Explanation:
- Salary is selected to appear in the table.
- ount(salary) - counts the occurrences of each salary.
- Group the records by
salary, meaning all records with the same value in thesalarycolumn will be grouped. count(salary)will count the grouped column. For example, three columns were grouped,count(salary)will return 3.
Common Pitfalls
It's crucial to specify columns correctly after group b y. For example, attempting to select a column not specified in group by will result in an error. for example:

In this example, an error occurs because job_id is selected but not included in group by.
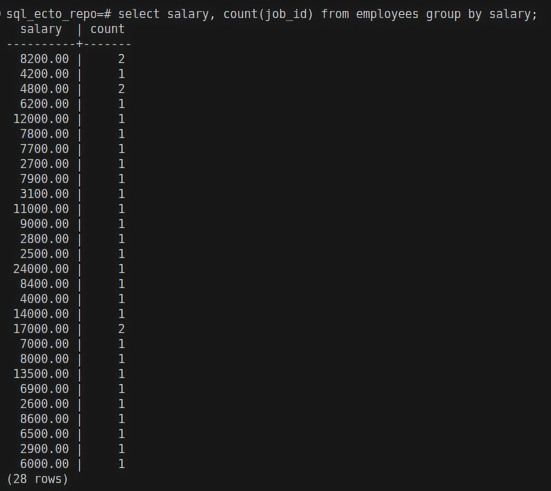
In the above example, after changing the query to:
select salary, count(job_id) from employees group by salary;
After changing job_id to salary from being selected, the query works as intended.
Ecto query for group by
In Ecto, use group_by/3 to achieve similar results:
group_by/3
Required arguments are:
- A schema
- Reference variable for the schema. Refer Aliases in Ecto to understand aliases/reference variables
- A field for group
Expression example
HR.Employee
|> group_by([e], e.salary)
|> select([e], %{"salary" => e.salary, "count" => count(e.job_id)})
|> HR.Repo.all()
The above query returns results from grouping HR.Employees records with the same salary
Explanation:
select([e], %{"salary" => e.salary, "count" => count(e.job_id)}) -> %{} is used because the results are wanted in a map. [e] is the reference variable. The map returns the grouped salary and the count of how many job_id share that salary.
Result:
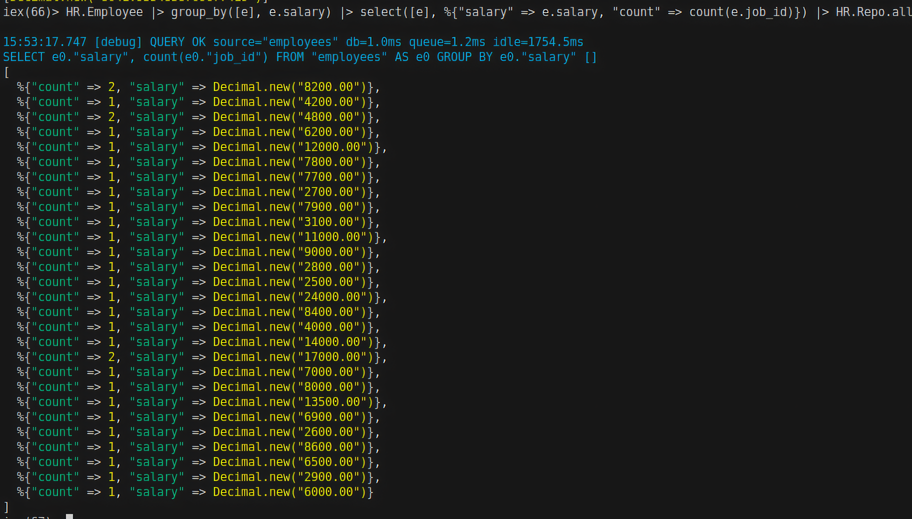
So, salary is grouped, and the count of how many job_id of employees with the same salary is determined.
Keywords
HR.Repo.all(from e in HR.Employee, group_by: e.salary, select: %{"salary" => e.salary, "count" => count(e.job_id)})
select: is a key. e is a value that is a reference variable for HR.Employee.